
Wer sich in der modernen IT-Landschaft umschaut, begegnet dort häufig Buzzwörtern wie Big Data, Data Analytics, Business Intelligence oder Data Engineering. Oft werden diese Begriffe miteinander vermischt und unterschiedlich interpretiert. Ob einem das Buzzword-Bingo zusagt oder nicht ist dabei egal. Es zeigt vor allem eines: Der Bedarf nach Daten in der IT-Industrie wächst.
Die Erfassung von Daten spielt besonders beim Betrieb von Infrastruktur eine große Rolle. Innerhalb der DevOps-Pipeline ist eine dedizierte Phase für das Monitoring vorgesehen. Nicht nur in unseren Projekten, sondern auch für unsere eigene Infrastruktur, ist diese Phase von essenzieller Bedeutung.
In diesem Blogbeitrag geht es darum, wie wir die unterschiedlichen Daten sammeln und persistieren. Zur Visualisierung der Daten haben wir uns für ein Service-Cluster um die Open Source Anwendung Grafana entschieden. Das Ziel ist es, durch Grafana den Überblick über unsere eingehenden Daten zu behalten.
In diesem Beitrag beantworten wir die folgenden Fragen:
- Warum nutzen wir Grafana? Welche Vorteile bietet die Anwendung?
- Wie sieht der Aufbau unseres Dienstes aus?
- Wie integrieren wir die Datenquellen?
Daten in der profi.com
In den letzten Jahren implementierten wir in unserer internen IT-Umgebung eine Vielzahl von Diensten. Frei nach dem Motto: „Eat your own dog food!“ evaluieren wir neue Anwendungen über einen langen Zeitraum, bevor wir unsere Kunden dazu beraten. Ein kurzer Umriss unserer internen Infrastruktur ist hilfreich, bevor wir uns mit Grafana auseinandersetzen.
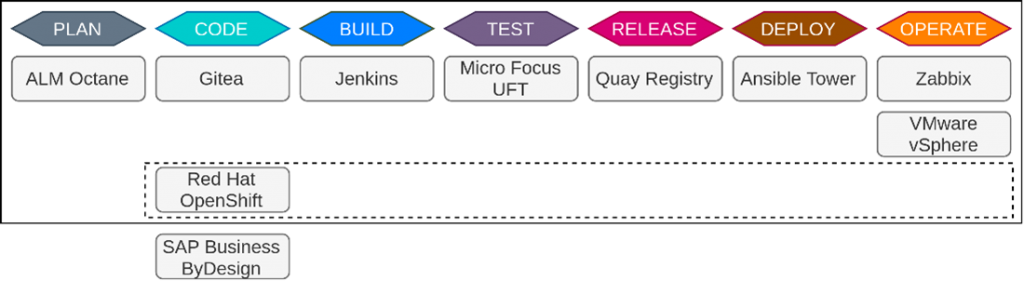
Für das Source Code Management nutzen wir Gitea. Unsere Projekte und Aufgaben verwalten wir mit ALM Octane. Zur Orchestrierung von Containern oder virtuellen Maschinen kommt vSphere und Red Hat OpenShift zum Einsatz. Die Überwachung unserer internen Infrastruktur erfolgt durch Zabbix. Zur unternehmensweiten Ressourcenplanung wird eine SAP-Lösung genutzt. Die Dienste sind Bestandteil unserer internen DevSecOps-LAB-Umgebung. Das Lab ist unsere interne Entwicklungsumgebung. Schaut dazu gern in den Blogbeitrag von Florian für einen umfangreichen Abriss der gesamten LAB-Infrastruktur.
Die LAB-Anwendungen erzeugen auswertbare Daten und stellen dafür verschiedene Schnittstellen zur Verfügung. Die besondere Herausforderung bei der Umsetzung ist die Integration unterschiedlicher API’s und Datenstrukturen. Jenkins stellt Metriken über einen Prometheus-API-Endpunkt zur Verfügung. Bei ALM Octane können Daten über eine JSON-REST-API abgefragt werden. Schnell zeigte sich, dass jeder Dienst eigene Schnittstellen bereitstellt. Bei der Datenerfassung war die Flexibilität der Lösung daher ein entscheidendes Kriterium.
Grafana
Grafana ist eine Open-Source-Applikation, die Daten aus unterschiedlichen Quellen visualisiert. Um Grafana hat sich seit der Erstveröffentlichung 2014 eine große Community gebildet. Der Dienst kann grundsätzlich frei genutzt werden. Wer Enterprise-Support oder erweiterte Funktionen wie SAML-Authentifizierung benötigt, kann Grafana Enterprise verwenden.
Grafana stellt ein Plugin-System bereit, das die Installation zusätzlicher Inhalte über ein zentrales Repository ermöglicht. Dort gibt es zusätzliche Datenquellen, Apps oder Panels zur Visualisierung der Metriken. Mit insgesamt 215 Plugins, lässt sich Grafana dadurch sehr flexibel konfigurieren (Stand: 28. Juni 2021).
Datenquellen
Unterschiedliche Datenquellen lassen sich durch entsprechende Plugins integrieren. Durch diese lassen sich vor allem die gängigen Datenbanksysteme anbinden. Dazu gehören Zeitreihendatenbanken wie InfluxDB, OpenTSDB oder Prometheus. Relationale Datenbanken wie MySQL, PostgreSQL und SQLite oder NoSQL-Datenbanken wie Redis, MongoDB und GraphQL werden ebenfalls unterstützt. Neben den Datenbanken lassen sich auch Metriken von Cloud-Providern oder statische Inhalte von REST-API’s in Grafana visualisieren.
Dashboards
In Grafana werden Daten in Dashboards visualisiert. Dashboards können beliebige Statistiken beinhalten. Dazu bietet Grafana typische Darstellungsformen wie Tabellen, Linien- oder Säulendiagramme. Darüber hinaus lassen sich auch komplexere Sachverhalte darstellen, indem man Daten in Heatmaps, Abhängigkeitsgraphen oder geografischen Karten anzeigt.
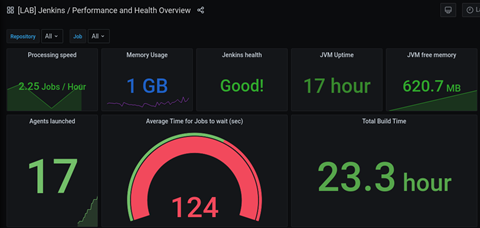
Die Dashboards lassen sich dynamisch anpassen. Man kann globale Filter setzen oder Zeitbereiche anpassen. Der Screenshot zeigt einen Ausschnitt unseres Jenkins-Dashboards, bei dem wir Filter implementiert haben. Durch die Auswahl eines Code-Repositorys werden so nur die Jenkins-Jobs für bestimmte Projekte dargestellt.
Plattformen
Grafana lässt sich auf Linux-, Windows- und Mac-Systemen installieren. Der Dienst kann außerdem als Docker-Image bereitgestellt werden. Dadurch lässt er sich flexibel auf beliebiger Infrastruktur einsetzen. Mit Grafana Cloud kann Grafana auch als SaaS-Anwendung benutzt werden. In unserem Fall ist die Cloud-Lösung für die interne Nutzung ungeeignet. Als Red Hat Partner und Freunde von Containern haben wir uns für das containerbasierte Deployment mit Podman entschieden.
Architektur
Grafana kann zwar mehrere Datenquellen integrieren, verfügt aber selbst über keine Datenbank, um Metriken zu persistieren. Stattdessen werden externe Datenbanken als Datenquellen eingesetzt. Die erste Herausforderung war daher die Wahl einer Datenbanktechnologie.
Besondere Anforderungen wie Hochverfügbarkeit, Ausfalltoleranz oder SLA’s waren dabei nicht relevant, da der Service nur als interne Testumgebung dient. Daher gab es keine Gründe gegen eine zentrale Speicherung der Daten. Das vereinfacht die Architektur des Dienstes gegenüber einer verteilten Lösung. Als Datenbank entschieden wir uns für eine Influx-Datenbank.
InfluxDB
InfluxDB lässt sich über das entsprechende Grafana-Plugin einfach integrieren. Sie zählt zur Kategorie der NoSQL-Datenbanken und bietet sich besonders für die Speicherung von Zeitreihen an. Das sind zeitlich geordnete Folgen, die Metriken über einen bestimmten Zeitbereich beschreiben. Beispiele für solche Zeitreihen sind u.a.:
- Festplattenauslastung von virtuellen Maschinen im letzten Quartal
- Der Verlauf des DAX-Index seit letztem Freitag
- Die Anzahl der öffentlichen Repositories auf Github seit Veröffentlichung der Plattform 2008
Viele interessante Daten über unsere interne Infrastruktur sind Zeitreihen. Im Gegensatz zu gängigen SQL-Datenbanken, wie MariaDB oder MySQL bietet InfluxDB spezielle Funktionen für Zeitreihen. Da die Daten einer Zeitreihe regelmäßig abgefragt werden, wächst der theoretische Speicherbedarf der Datenbank kontinuierlich. Zur Lösung des Problems nutzt InfluxDB Downsampling und Retention.
Retention & Downsampling
Beim Downsampling wird die Auflösung der Daten reduziert, wenn diese älter werden. Betrachtet man zum Beispiel die Netzwerkauslastung eines Dienstes vor zwei Jahren, dann genügt es oft, wenn man nur noch tägliche Werte speichert. Betrachtet man dieselbe Zeitreihe jedoch im Verlauf der letzten Stunden, sollte die Datenauflösung höher sein, um sie beispielsweise für Warnungen zu nutzen. Retention kann zusätzlich eingesetzt werden. Das ermöglicht die Definition eines Ablaufdatums für Datenpunkte. Sind Daten zum Beispiel älter als drei Monate, werden sie von InfluxDB automatisch gelöscht.
Mit Retention und Downsampling bietet InfluxDB sinnvolle Wege, um mit Zeitreihendaten umzugehen.
Eine letzte Frage bleibt: Wie kommen die Daten in die Datenbank?
Telegraf
Diese Frage haben sich wohl auch die Entwickler von InfluxDB gestellt. Ihre Lösung heißt Telegraf. Telegraf ist ein agent-basiertes Tool, das Daten aus unterschiedlichen Quellen sammelt und weiterverarbeitet. Wie Grafana verfügt auch Telegraf über ein erweiterbares Plugin-System. Über 200 Plugins für Telegraf helfen bei der Anbindung unterschiedlicher Schnittstellen. Es gibt auch ein Plugin für die Anbindung einer InfluxDB. Dieses schreibt die gesammelten Daten automatisch in die Datenbank.
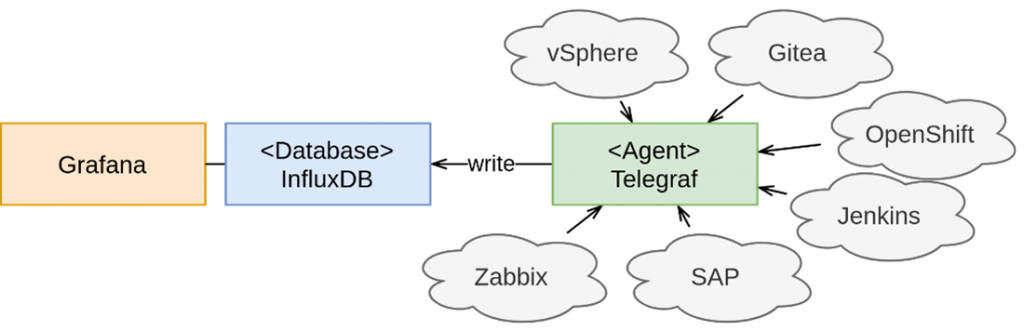
Die Anbindung der Datenbank erfolgt über eine einfache minimale Konfigurationsdatei:
[[outputs.influxdb_v2]]
urls = ["http://influxdb:8086"]
## Token zur Authetifizierung
token = "${DOCKER_INFLUXDB_INIT_ADMIN_TOKEN}"
## Organisation innerhalb der InfluxDB
organization = "${DOCKER_INFLUXDB_INIT_ORG}"
## Ziel-Bucket (Datenbank)
bucket = "${DOCKER_INFLUXDB_INIT_BUCKET}"Erfasste Daten können nun von Telegraf in die InfluxDB geschrieben werden. Die Datenquellen lassen sich ebenfalls über die Konfigurationsdatei definieren. Je nach Schnittstelle bietet Telegraf dazu unterschiedliche Plugins.
REST-APIs
Viele moderne Applikationen stellen Daten über REST-APIs bereit. Dazu gehören u.a. Gitea, SAP und ALM Octane. REST-APIs lassen sich in Telegraf mit dem HTTP-Plugin abrufen und in die InfluxDB schreiben. Folgendes Beispiel zeigt die Konfiguration, mit der wir einen Snapshot der aktuellen Repositories in Gitea abfragen:
[[inputs.http]]
name_override = "gitea_repositories"
data_format = "json"
json_query = "data"
tag_keys = ["id", "name", "full_name"]
urls = [ "${GITEA_HOST}/repossearch" ]Prometheus-API
REST-APIs ermöglichen die Abfrage von Informationen zum Zeitpunkt der Abfrage und deren Antworten im JSON-Format bieten sich nicht immer für die Persistierung als Zeitreihe an. JSON-Objekte sind in der Regel hierarchisch aufgebaut. Informationen können durch komplexe JSON-Path-Ausdrücke extrahiert werden. Der Aufwand variiert je nach Datenstruktur.
Geeigneter ist stattdessen das Prometheus-Format, das Metriken so bereitstellt, dass sie direkt zur Erstellung von Zeitreihen genutzt werden können. Die Daten sind als Liste mit Key-Value-Paaren abrufbar. Jeder einzelne Eintrag kann direkt mit dem aktuellen Zeitstempel in die Datenbank übertragen werden. Folgendes Code-Beispiel zeigt einen Ausschnitt der Prometheus-Schnittstelle unseres internen Jenkins-Dienstes:
# TYPE jenkins_task_scheduled_total counter
jenkins_task_scheduled_total 113.0
# TYPE jenkins_runs_success_total counter
jenkins_runs_success_total 80.0Über das Prometheus-Plugin lassen sich diese Daten sehr einfach in die InfluxDB übertragen:
[[inputs.prometheus]]
urls = [ "${JENKINS_HOST}/prometheus/" ]Weitere Schnittstellen
Für einige Dienste, wie zum Beispiel vSphere, bietet Telegraf dedizierte Plugins, welche die Integration der Daten erleichtern. Diese existieren unter anderem für Elasticsearch, Icinga2 oder AWS CloudWatch. Folgendes Beispiel zeigt einen Ausschnitt der Integration unserer internen vSphere-Umgebung:
[[inputs.vsphere]]
vcenters = ["${JENKINS_HOST}/sdk/"]
username = "${VSPEHRE_USERNAME}"
password = "${VSPEHRE_PASSWORD}"Wie geht es weiter?
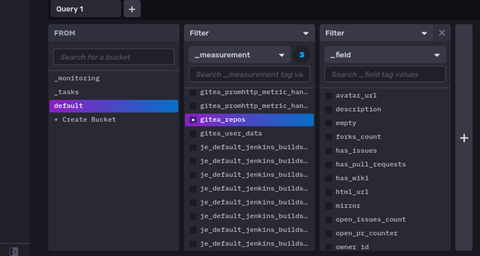
Mit der Hilfe von Telegraf gelangen die Daten nun in die InfluxDB. Wie in folgendem Bild zu sehen ist, werden die Daten erfolgreich persistiert und sind über die InfluxDB-Weboberfläche sichtbar.
In Grafana kann man die Daten nun zur Visualisierung von Dashboards nutzen. An dieser Stelle wollen wir aber noch nicht zu viel verraten. Die Gestaltung von Dashboards in Grafana verdient einen eigenen Artikel. Darin erklären wir, welche Dashboards wir zum Monitoring unserer Infrastruktur erstellt haben. Außerdem zeigen wir, wie man Datenquellen direkt in Grafana integriert, ohne Telegraf als Agent zu benötigen.

