
In der heutigen vernetzten Welt sind KI-Übersetzer wie DeepL und Google Translate nicht mehr wegzudenken. Im vorherigen Kapitel habe ich diese Übersetzer bereits auf Herz und Nieren getestet. Doch wie bei allen Technologien birgt auch die Nutzung von KI-Übersetzern bestimmte Risiken. In diesem Kapitel schließe ich meine Blog-Reihe ab und werfe einen genaueren Blick auf diese Risikofaktoren und wie sie minimiert werden können.
Wenn sich Sprache verändert
Sprache ist im ständigen Wandel. Nicht nur der Stil, sondern auch die Regeln der deutschen Sprache haben sich in den vergangenen Jahren erheblich gewandelt. Neue Wörter und Phrasen wurden eingeführt (Jugendwort des Jahres 2023: „Goofy“), während andere veraltet und weniger gebräuchlich geworden sind. Die Einflüsse von Technologie, sozialen Medien und kulturellem Austausch haben zu einer schnellen Evolution der Sprache geführt. Darüber hinaus haben sich auch die Grammatik und die Rechtschreibung weiterentwickelt, um die Veränderungen in der Gesellschaft und der Kommunikation widerzuspiegeln.
Damit diese Trends und Entwicklungen auch in den Übersetzungen abgebildet werden können, müssen die KI-Übersetzer stets auf dem neusten Stand gehalten werden, besonders die Trainingsdaten. Das System lernt anhand der Trainingsdaten, mit unbekannten Texten umzugehen und diese in einer Weise zu interpretieren, die sowohl den Kontext als auch die Nuancen des Originaltextes berücksichtigt. Sind diese Daten nicht aktuell, könnte das System Übersetzungen liefern, die nicht mehr zeitgemäß sind.
Der richtige Umgang mit Nutzerfeedback
Sogenannte Feedback-Loops ermöglichen es Systemen, aus Fehlern zu lernen und die eigene Leistung im Laufe der Zeit zu verbessern. Wenn ein KI-Übersetzer einen Text falsch übersetzt, kann ein Benutzer des Systems beispielsweise diese Übersetzung als „schlecht“ markieren und eine alternative „richtige“ Übersetzung vorschlagen. Dadurch kann das System die vorgeschlagene „richtige“ Übersetzung verwenden, um seine internen Modelle anzupassen und zu verbessern. Dieser Prozess der kontinuierlichen Verbesserung ermöglicht es dem KI-Übersetzer, seine Fähigkeiten im Laufe der Zeit autonom zu verfeinern und genauer zu werden. Es ist jedoch wichtig zu beachten, dass die Qualität des Feedbacks – also ob eine Übersetzung als gut oder schlecht markiert wird – und die Genauigkeit der vorgeschlagenen „richtigen“ Übersetzung einen erheblichen Einfluss auf diesen Prozess haben. Falsches oder irreführendes Feedback, egal ob absichtlich oder unabsichtlich, könnte dazu führen, dass das System inkorrekte Übersetzungen als korrekt interpretiert, diese Fehler in zukünftigen Übersetzungen wiederholt oder sogar beleidigende Inhalte in das System eingebettet werden.
Damit das nicht passiert, sollten diese Feedbacks sorgfältig überprüft und moderiert werden. Das könnte eine Kombination aus automatisierten Systemen und menschlichen Prüfern sein. Auf diese Weise kann das Risiko minimiert werden, dass falsches oder irreführendes Feedback die Leistung oder die Genauigkeit des KI-Übersetzers beeinträchtigt.
Ergebnisse müssen geprüft werden
In jedem KI-System kann es zu sogenannten „Overfitting“ (dt. „Überanpassung“) kommen. Overfitting tritt auf, wenn ein Modell so sehr an die Trainingsdaten angepasst ist, dass es an Flexibilität verliert und bei neuen, unbekannten Daten schlecht abschneidet. Dadurch lernt das KI-System nicht, die zugrundeliegenden Muster zu erkennen. Das führt zu ungenauen Vorhersagen und einer schlechten allgemeinen Leistung des Modells.
Um sicherzustellen, dass dieses Verhalten bei einem Systemtest erkannt wird, sollte ein separater, unabhängiger Testdatensatz verwendet werden, der nicht für das Training benutzt wurde – oder besser gesagt, nicht benutzt werden kann. Im vorherigen Kapitel habe ich bereits auf dieses Thema aufmerksam gemacht.
Angriff auf persönliche Daten
Wie schon zuvor genannt, werden Trainingsdaten benötigt, damit ein KI-System überhaupt funktionieren kann. Dabei sollte man jedoch sicherstellen, dass diese Daten keine personenbezogenen oder privaten Informationen beinhalten, etwa wie Namen, Adressen, Telefonnummern oder andere identifizierende Merkmale. Werden diese Daten dennoch für das Training eines KI-Systems verwendet, besteht das Risiko, dass die Privatsphäre der betroffenen Personen verletzt wird. Denn ein Angreifer könnte potenziell Zugang zu diesen Daten erlangen und sie für unerwünschte Zwecke missbrauchen.
Um gezielte Werbung, Identitätsdiebstahl oder gar Erpressung durch den Einsatz eines KI-Systems zu verhindern, sollten alle mit der KI in Verbindung stehenden Daten anonymisiert werden – darunter vor allem Trainingsdaten. Die Bereinigung der Daten sollte auch Bestandteil der Feedback-Loop sein. Sonst besteht ebenfalls die Gefahr, dass eingegebene Informationen ungefiltert weiterverwendet werden.
Weitere Risiken
Die bisher genannten Aspekte stellen nur eine kleine Auswahl der Risiken dar. Weitere Risiken sind:
- Fehlende Barrierefreiheit: Menschen mit Behinderungen können Schwierigkeiten haben, die Systeme zu nutzen – insbesondere Personen mit Seh- und Hörbehinderungen. Es ist wichtig, dass die KI-Systeme barrierefrei gestaltet werden, damit sie für alle Benutzer zugänglich und nutzbar sind.
- Verlust von Kontext: Menschliche Kommunikation enthält feine Nuancen. Werden diese nicht erfasst, kann dies zu Missverständnissen und Fehlkommunikation führen, insbesondere bei komplexen und sensiblen Themen.
- Abhängigkeit von Internetverbindung: Viele KI-Systeme erfordern eine stabile Internetverbindung, damit diese überhaupt benutzt werden können. Das kann ein Hindernis für Benutzer in Gebieten mit schlechter oder keiner Internetverbindung sein.
- Fehlende kulturelle Sensibilität: KI-Übersetzer sollten kulturelle Unterschiede und spezifische regionale Ausdrücke berücksichtigen, damit keine unangenehmen oder beleidigenden Übersetzungen entstehen.
- Unzufriedenheit der Benutzer: Erfüllen KI-Systeme nicht die Erwartungen der Benutzer, kann das zu Unzufriedenheit führen. Faktoren, die dafür eine Rolle spielen, sind beispielsweise ungenaue Übersetzungen, eine langsame Reaktionszeit, fehlende Unterstützung von Dialekten, Jargons oder Fachsprachen oder eine schwierige Benutzeroberfläche.
- Fehlende Interpretierbarkeit der Ergebnisse: Beim maschinellen Lernen ist die Methode, wie KI-Systeme Ergebnisse generieren, nicht immer klar. Das kann bei Benutzern zu Verwirrung führen, insbesondere wenn eine Übersetzung ungenau oder unerwartet ist. Deshalb ist es wichtig, die Systeme transparent und interpretierbar zu gestalten, so dass Vertrauen und das Verständnis der Benutzer gefördert werden.
Bewertung der Risiken
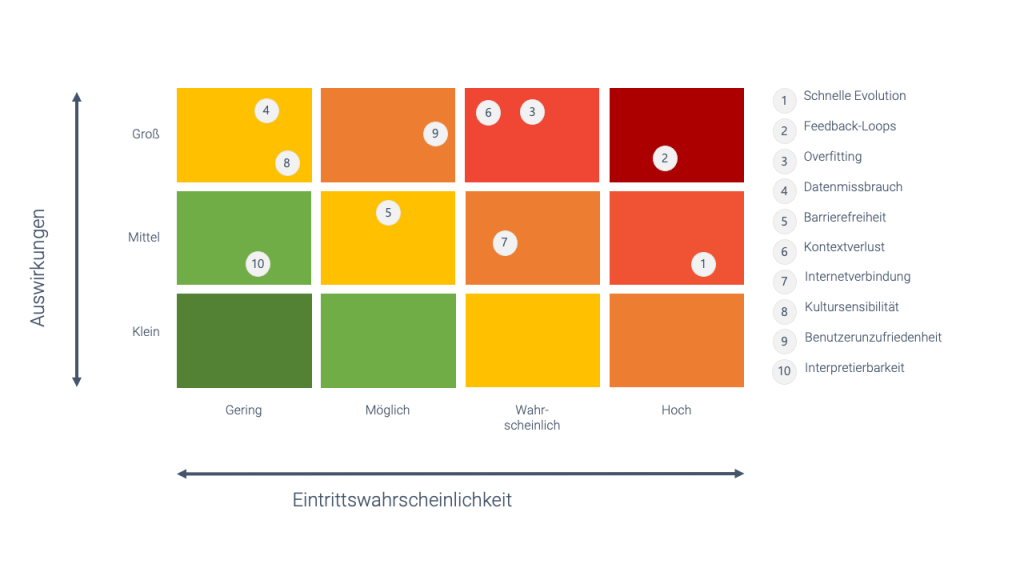
Am Ende meiner Betrachtung habe ich alle Aspekte hinsichtlich ihrer Auswirkungen und Eintrittswahrscheinlichkeit gegenübergestellt und gegeneinander abgewogen. Damit ist eine gezielte Priorisierung der Risiken möglich. Wichtig ist, dass diese Darstellung sehr vereinfacht ist und nur meine persönliche Wahrnehmung auf der Grundlage der Erfahrungen wiedergibt, die ich während meiner Reise zum Thema „Testen von KI“ gemacht habe.
Eine Reise geht zu Ende
In Anbetracht der beschriebenen Risiken ist es wichtig, dass die Entwicklung und der Einsatz von KI-Systemen verantwortungsbewusst und mit größter Sorgfalt erfolgt. Das gilt für KI-Übersetzer, wie auch für andere Systeme, die künstliche Intelligenz nutzen. Bei anderen Systemen müssen jedoch noch viele weitere Risiken betrachtet werden. Weitere Informationen dazu bietet die ISTQB-Zertifizierung zum Testen von künstlicher Intelligenz. Durch die Berücksichtigung dieser Risikofaktoren können Entwickler das volle Potenzial der KI-Übersetzer nutzen und gleichzeitig die Privatsphäre und die Qualität von Übersetzungen schützen.
Abschließende Worte
Mit diesem Kapitel endet meine Reise durch die Welt des KI-Testens. Rückblickend haben mir die ersten Experimente mit der „Teachable Machine“ aus dem ersten Kapitel sehr geholfen, die Funktionsweise des maschinellen Lernens besser zu verstehen. Die Analyse der KI-spezifischen Qualitätsmerkmale und die anschließende Integration der Testfälle in ALM Octane in den folgenden Kapiteln bilden zusammen mit der Risikoanalyse einen runden Abschluss. Ich bleibe gespannt, was die Zukunft an interessanten KI-Themen bereithält.

