
Bevor wir uns jedoch im Detail mit den Containern befassen, werfen wir zuerst einen Blick auf die Anwendung und ihre Architektur.
Die Applikation: Der Scrummaster
Die Anwendung, Scrummaster, ist eine Inhouse-Applikation, die uns beim Planning Poker und Retrospektiven unterstützt. Ja, die Anwendung heißt Scrummaster. Um mögliche Verwirrung mit der Rolle im Scrum zu reduzieren, werden wir im nachfolgenden einfach von der Anwendung sprechen. Die Anwendung wurde intern durch Mitarbeiter:innen und Werkstudierende der profi.com entwickelt und dient als Beispielprojekt bei Trainings und Workshops.
Wie immer, lohnt es sich zuerst einen Blick auf die Anwendung und deren Funktionen zu werfen. Das sollte bei Containerisierungs- und Migrationsprojekten ebenfalls an erster Stelle stehen, bevor man sich mit Architektur und Implementierung auseinandersetzt.
Features
Die Anwendung unterstützt unsere Teams bei zwei häufigen Events im Scrum: bei der Retrospektive und dem Planungspoker im Sprint Planning. Sie besticht durch einfache Bedienelemente und beschränkt sich auf die Grundfunktionen für beide Scrum-Events. Ohne Registrierung oder Login können Räume erstellt werden, in denen die Teams gemeinsam arbeiten.
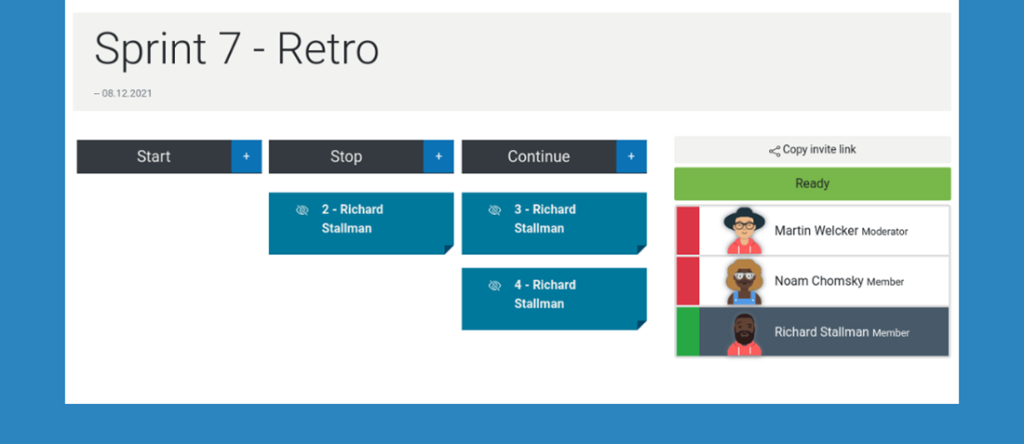
Beim Planungspoker stehen verschiedene Kartendecks zur Verfügung, so zum Beispiel T-Shirtgrößen (siehe Screenshot) oder die gängigen Fibonacci-Zahlen. Für die Retrospektive stehen ebenfalls mehrere Spaltenlayouts zur Verfügung. In der Abbildung ist das übliche „Start, Stop, Continue“– Layout zu sehen.
Um das kollaborative Arbeiten zu ermöglichen, findet die Kommunikation beinahe in Echtzeit statt.

Architektur
Vorab: In diesen Blogbeitrag befassen wir uns nicht ausführlich mit der Applikation und dem Anwendungscode. Stattdessen genügt ein kurzer Einblick in die Architektur und ein Überblick über die Container, mit denen die Anwendung bisher ausgerollt wird.
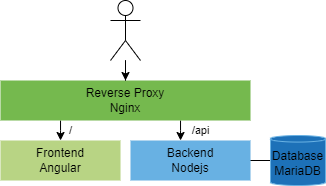
Die Anwendung wurde als 3-Tier-Webanwendung, also als Monolith implementiert. Obwohl diese Architektur in der Praxis teilweise durch Mikroservice-Architekturen verdrängt wird, ist sie dennoch beliebt und oft anzutreffen. Da wir in den meisten Projekten mit ähnlichen Topologien konfrontiert sind, haben wir uns bei dieser Anwendung ebenfalls dafür entschieden.
Das Webfrontend wurde mit Angular, dem Frontend-Framework von Google, entwickelt. Es bildet den Presentation-Layer mit HTML und JavaScript zur Darstellung der Anwendung im Browser.
Das Frontend kommuniziert mit dem Backend. Dieses beinhaltet die Business-Logik der Anwendung und läuft in der Node.js-Laufzeitumgebung. Die Kommunikation zwischen Frontend und Backend geschieht über eine REST-API und Websockets. Die Websocket-Schnittstelle ermöglicht eine beinahe echtzeitfähige Kommunikation zwischen dem Backend und mehreren Clients.
Das Backend speichert Anwendungsdaten in einer MariaDB-Datenbank. Dort werden unter anderem Poker-Decks, deren Karten und Session-Informationen sowie Abstimmungsergebnisse abgelegt.
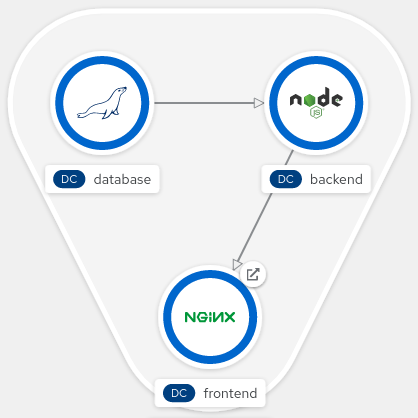
Diese drei Services Frontend, Backend und Datenbank bilden die 3-Tier Applikation. Um Routing und TLS-Terminierung und Caching zu zentralisieren, wird ein Nginx-Webserver als Reverse-Proxy verwendet.
Containerisierung
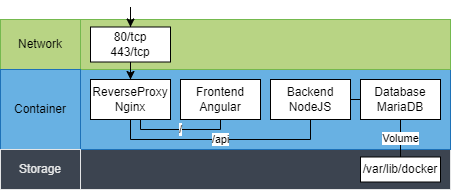
Die Anwendung wird bisher auf einer virtuellen Maschine mit Docker und docker-compose bereitgestellt. Die vier Dienste laufen als einzelne Container in einem Docker-Netzwerk. Damit die Datenbank ihre Daten nach dem Neustart oder Update des Containers halten kann, wird ein Docker-Volume genutzt. Die vollständige Architektur ist in folgendem Diagramm zu sehen:
Warum OpenShift?
In den letzten Beiträgen unserer Blogreihe haben wir zahlreiche Vorteile von OpenShift bei der Arbeit mit Containern vorgestellt. Unterschiede beim Umgang mit Docker und OpenShift wurden von unterschiedlichen Perspektiven analysiert. Betrachten wir diese Fragestellung nun im Hinblick auf die Scrummaster-Anwendung.
Die Applikation wurde über ein Jahr erfolgreich auf einer virtuellen Maschine mit Docker betrieben. Was sind unsere Gründe für den Umzug auf OpenShift?
An erster Stelle wollen wir die Applikation nach OpenShift migrieren, um praktische Erfahrungen mit dem Migrationsprozess zu sammeln. Davon könnt ihr im nächsten Abschnitt des Artikels profitieren, wenn wir uns detaillierter mit den Hürden der Migration auseinandersetzen.
Der Umzug hat natürlich weitere positive Effekte. Bisher konnte die Anwendung nicht ohne Downtime betrieben werden. Wartungsfenster der virtuellen Maschine oder Updates der Applikation sorgten dafür, dass die Anwendung vorübergehend nicht nutzbar war. Mit OpenShift und Zero Downtime Deployments können wir das Problem lösen. Im Beitrag von Ronny Lubke habt ihr bereits erfahren, welche Möglichkeiten (Blue/ Green, Canary, etc.) ihr beim Deployment habt.
Mit OpenShift können wir benötigte Ressourcen besser und dynamischer skalieren. Dazu findet ihr weitere Informationen in Silvios Blogbeitrag.
Die Plattform hilft uns ebenfalls bei der Gestaltung unserer CI-/CD-Pipeline. Während wir für Integrationstests bisher immer die Produktivdatenbank genutzt haben, können wir in OpenShift schnell und einfach beliebig viele Test-Container erstellen und nach der Testdurchführung wieder entfernen.
Herausforderungen
Bei der Migration der Anwendung in unsere interne OpenShift-Umgebung stießen wir auf einige Herausforderungen. Damit ihr bei euren Migrationsprojekten weniger Schwierigkeiten habt, nehmen wir euch Schritt-für-Schritt mit und erklären wie wir auftretende Probleme gelöst haben.
Container Rollout
Vor der Migration bestand die gesamte Applikation aus vier Container (Frontend, Backend, Datenbank, Reverse Proxy). Für das Deployment der Anwendung wurde das CLI-Tool docker-compose genutzt, um alle vier Container mit Netzwerk- und Volume-Konfiguration bereitzustellen. Im Folgenden ist eine vereinfachte Version unseres docker-compose.yml, das definiert, wie die Container bereitgestellt werden:
version: '3'
volumes:
db_data:
services:
frontend:
build: ./frontend
backend:
build: ./backend
env_file:
- ./credentials.env
database:
image: mariadb
volumes:
- db_data:/var/lib/mysql
env_file:
- ./credentials.env
proxy:
build: ./proxy
ports:
- 80:80
- 443:443Für die Datenbank wird das Volume db_data bereitgestellt, damit die Daten auch nach Update oder Redeployment persistent sind. Danach werden die vier Container definiert. Nur der Proxy-Container verfügt über ein Portmapping und ist außerhalb des Container-Netzwerks erreichbar. Ein Netzwerk für alle Container wird durch docker-compose implizit angelegt. Eingehender Traffic wird durch den Container an den Backend- oder Frontend-Container weitergeleitet. Während der Datenbank-Container auf Basis des offiziellen MariaDB-Images von Docker-Hub basiert, hatten wir für die weiteren Services Dockerfiles angelegt. Diese Images wurden ursprünglich zur Ausführungszeit von docker-compose up gebaut.
Docker-compose zu OpenShift
Die docker-compose.yml bietet eine gute Grundlage für die Migration der Applikation nach OpenShift. Mit dem Kommandozeilentool Tool Kompose lassen sich Service-, Deployment-Konfigurationen und Configmaps automatisch aus einer docker-compose.yml-Datei erstellen:
$ kompose convert -f docker-compose.yaml
INFO Kubernetes file "backend-service.yaml" created
INFO Kubernetes file "database-service.yaml" created
INFO Kubernetes file "frontend-service.yaml" created
INFO Kubernetes file "backend-deployment.yaml" created
INFO Kubernetes file "backend-database-credentials-env-configmap.yaml" created
[...]Wir haben mit Kompose durchwachsene Erfahrungen gemacht und die Konfiguration für OpenShift ohne das Tool, manuell erstellt. Interessiert ihr euch dafür wie man Konfigurationsdateien in OpenShift erstellt, erfahrt ihr mehr dazu in Silvios Beitrag „Multi-Container Rollout as Code“.
Secrets
Beim Deployment mit docker-compose wurden die Zugangsdaten der Datenbank als Umgebungsvariablen in die Container gereicht (siehe docker-compose.yml, Zeile 12 u. 19). Zur Definition der Variablen wurde dazu eine credentials.env-Datei übergeben. Wie wir im Beitrag von Lara Bischoff „Container Secrets – warum und wie?“ gelernt haben, gibt es dazu auch außerhalb von OpenShift wesentlich bessere Optionen. Bei der Migration nach OpenShift muss die credentials.env durch eine Secret Map ersetzt werden.
Image Streams, Registries und Pipelines
Mit docker-compose wurden die Images für Frontend, Backend und Proxy beim Starten der Anwendung mit docker-compose up gebaut. Bei der Migration nach OpenShift ist das nicht mehr realisierbar. OpenShift nutzt Imagestreams und bietet damit Möglichkeiten, Container laufend zu aktualisieren, wenn sich deren Images aktualisiert haben. Dafür ist es obligatorisch, dass die Images nach dem Bauen in einer zentralen Image-Registry abgelegt werden.
OpenShift prüft regelmäßig, ob neue Images vorhanden sind und kann diese bei Bedarf ausrollen. Die Voraussetzung dafür ist, dass regelmäßige Image-Updates in einer Registry eingecheckt werden. Als Image-Registry nutzen wir intern die Quay Registry von Red Hat.
Der Release neuer Versionen sollte stets automatisiert geschehen. Dafür nutzen wir Jenkins als Pipeline-Tool, das nach erfolgreicher Durchführung der Pipeline die neuen Images für Frontend, Backend und Datenbank in die Quay Registry bereitstellt. Die neuen Images werden dann durch OpenShift deployt. Continous Deployment macht jedoch Quality Gates erforderlich. Wir haben in unserer Pipeline mehrere Prüfungen eingebaut.
Zuerst verifizieren wir mit statischer Analyse durch Linter die syntaktische und formale Korrektheit des Codes. Danach werden Unit- und Integrationstests durchgeführt. Da das Backend für Integrationstests Zugriff zur Datenbank benötigt, wird zuerst ein temporärer Datenbankcontainer auf Basis des aktuellen Images erstellt.
Sind die Tests erfolgreich, wird der Quellcode noch durch Sonarqube geprüft. Ist diese Prüfung erfolgreich, werden alle Images gebaut und in der Quay-Registry abgelegt. Die gesamte Pipeline ist in folgendem Abbild zu sehen:

Ein vollständiger Durchlauf der Pipeline benötigt zirka 12-15 Minuten. Eine kürzere Ausführungszeit könnte durch eine stärkere Parallelisierung der Phasen erreicht werden. So ließe sich zum Beispiel das Bauen der Images parallelisieren. Automatisierte Akzeptanztests, zum Beispiel mit Selenium oder Cypress wären außerdem eine sinnvolle Erweiterung der Pipeline.
Networking
Die Migration nach OpenShift erfordert auch Anpassungen bei der Netzwerkkonfiguration. Für die TLS-Terminierung wurde zuvor ein dedizierter Nginx-Container als Reverse Proxy eingesetzt. Diese Aufgabe kann durch OpenShift Routes und Services übernommen werden. Den Schlüssel für das Zertifikat kann man in der Route definieren. Der dedizierte Nginx-Container wurde demnach entfernt.
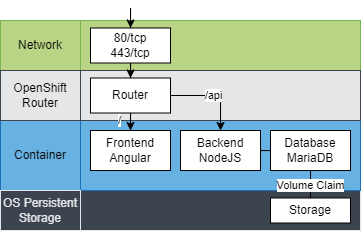
In OpenShift gibt es neben Services und Routes auch noch Ingresses für das Routing. Diese haben wir in unserem Fall nicht benötigt. Wenn ihr wissen wollt, was der Unterschied zwischen Ingresses und Services ist, könnt ihr den Blogbeitrag von Johannes Stieber zu Container Networking lesen.
Rootless / Rootful
Container sollten stets ohne Root-Berechtigungen ausgeführt werden. Dazu gehört, dass man auch innerhalb des Containers auf Root-Berechtigungen weitestgehend verzichtet. OpenShift zwingt den Nutzer zur Einhaltung der Best Practices und verbietet sogar die Nutzung des root-Users im Container. Viele offizielle Docker Images von Docker-Hub nutzen jedoch den Root-User und sind daher oft nicht ohne Weiteres in OpenShift nutzbar.Bei der Gestaltung des Dockerfiles hatten wir ursprünglich nicht darauf geachtet. Folgendes Dockerfile wurde für die Erstellung des Node-Backend-Images genutzt:
FROM node:14
# Copy source code
COPY ./lib /home/node/app/lib/
COPY ./backend /home/node/app/backend/
WORKDIR /home/node/app/backend
# Install dependencies
RUN yarn install
# Launch application
EXPOSE 8080
ENTRYPOINT yarn prodStandardmäßig werden die Schritte im Dockerfile durch den Root-User ausgeführt. In OpenShift würde die Ausführung des Containers daher Probleme bereiten. Abhilfe schaffen folgende beiden Befehle zu Beginn des Dockerfiles, bei denen man zuerst einen Nicht-Root-Nutzer anlegt und die Anweisungen dann mit ihm ausführt, wie Martin Fischer in seinem Beitrag „Rootful oder rootless?„ erklärte:
RUN groupadd -r <user> && useradd --no-log-init -r -g <user> <user>
USER <user>[:<group>]Eine elegante Alternative bietet Red Hat selbst: im Katalog mit vorgefertigten Container-Images, die alle rootless in OpenShift nutzbar sind. Die Images stellen einen rootless-Nutzer zur Verfügung, der Berechtigungen für einige Pfade innerhalb des Images erhält. Detaillierte Anweisungen zur Nutzung findet man in der Dokumentation der Images.
Unser ursprüngliches Dockerfile musste nur minimal angepasst werden. Statt des Node-Images von Dockerhub haben wir das Image vom Red Hat-Katalog genutzt. Das Image nutzt /opt/app-root/src standardmäßig als Arbeitsverzeichnis. Im Dockerfile haben wir auf die absoluten Pfadangaben verzichtet (Zeile 4-7) und legen den Quellcode über die relative Pfadangabe direkt im Arbeitsverzeichnis ab.
Statt yarn haben wir npm zur Installation der Abhängigkeiten und Ausführung der Anwendung genutzt, da die Installation von Yarn Root-Privilegien im Image benötigt und npm bereits im Basis-Image vorhanden war.
FROM registry.redhat.io/rhel8/nodejs-14
# Copy source code
COPY ./lib ./lib
COPY ./backend ./backend
WORKDIR ./backend/
# Install dependencies
RUN npm install
EXPOSE 8080
ENTRYPOINT npm run -d prodNach den drei Anpassungen konnte das Image in OpenShift genutzt werden. Bei der Nutzung ist darauf zu achten, dass ein Red Hat-Account nötig ist, um Images von registry.redhat.io zu verwenden. Alternativ kann man die Images von registry.access.redhat.com ohne Account beziehen. Images, für die man eine Red Hat Subscription benötigt, erhält man von hier jedoch nicht. Wer keinen Account und keine Subscription hat, muss daher zum Beispiel auf folgendes Image zurückgreifen: registry.access.redhat.com/ubi8/nodejs-14.
Lessons learned
Nachdem alle die gezeigten Herausforderungen gelöst wurden und nach einigen kleineren Anpassungen, konnte die Applikation, der Scrummaster, erfolgreich in OpenShift deployt werden. Das größte Kopfzerbrechen bereitete uns die Rootless-Problematik. Hier hatten wir unterschiedliche Ansätze ausprobiert. Die Nutzung der offiziellen Red Hat-Basisimages war in unserem Fall die sinnvollste Lösung.
Viele Migrationsschritte waren unproblematisch, wenn man mit den Besonderheiten der OpenShift-Plattform vertraut ist, so zum Beispiel die Implementierung von Services, Routes und Secrets.
Je nach Aufbau und Architektur der Anwendung variiert der individuelle Migrationsaufwand stark. Eine große Erkenntnis hierzu war, dass der Aufwand dort besonders groß war, wo Services besonders stark miteinander gekoppelt waren. Schwach gekoppelte Dienste, wie in unserem Fall die Datenbank, bereiteten bei der Migration kaum Probleme.
Relativ großen Migrationsaufwand hatten wir beim Entfernen des Proxy-Containers durch Timeouts der WebSocket-Verbindungen. WebSocket-Verbindungen werden standardmäßig nach etwa einer Minute geschlossen, wenn keine Anfragen gesendet werden. Üblicherweise implementiert man ein Ping-Pong-Verfahren (RFC 6455), um das Schließen der Verbindung zu vermeiden. Das Verfahren wurde bei der Anwendung jedoch nicht implementiert. Im Betrieb wurde das Problem gelöst, indem das Timeout für WebSocket-Verbindungen beim Reverse Proxy auf 24 Stunden angehoben wurde.
Da der Proxy beim Betrieb im OpenShift nicht mehr nötig war und daher entfernt wurde, kam es zu regelmäßigen Timeouts beim Planning Poker oder in Retros. Die Identifikation des Fehlers kostete viel Zeit und erforderte zusätzliche Implementierungen am Frontend und Backend. Die Ursache war, dass die Funktionsfähigkeit des WebSockets nur durch den Proxy gewährleistet wurde. Unser Problem hat schön illustriert: Schwach gekoppelte Services lassen sich wesentlich leichter migrieren.
Fazit
Mit diesem praktischen Beispiel endet unsere Serie zu Docker, Kubernetes und OpenShift vorerst. In insgesamt zwölf Beiträgen von zehn verschiedenen Autoren haben wir Container in all ihren Facetten betrachtet.
Startet ihr gerade damit Container zu nutzen oder arbeitet ihr bereits länger mit ihnen? Lest gern auch die anderen Beiträge unserer Reihe, die euch ein umfangreiches Grundlagenwissen vermitteln.
Habt ihr Fragen zu unseren Beiträgen oder individuelle Probleme und benötigt dafür Hilfe? Fragt dazu gern unsere Experten oder schickt uns eine Mail.

