
Nachdem sich der letzte Beitrag unserer Veröffentlichungsreihe „Docker vs. OpenShift“ mit dem Thema Docker beschäftigt hat, gibt es diesmal eine kurze Einführung zu OpenShift und das zugrunde liegende Kubernetes.
OpenShift ist eine der führenden Kubernetes-Anwendungsplattformen und wurde von Red Hat für eine offene Hybrid-Cloud-Strategie entwickelt. OpenShift bietet eine auf Sicherheit ausgerichtete, einheitliche Basis zur ortsunabhängigen Bereitstellung von Anwendungen sowie optimierte Entwickler-Workflows für eine schnelle Markteinführung. So umfasst es alles, was für die Entwicklung und Bereitstellung von Hybrid-Clouds, Unternehmens-Containern sowie Kubernetes notwendig ist. Deshalb lässt es sich auch auf beliebigen Clouds, ob Private oder Public Cloud-Infrastrukturen, ausführen/nutzen.
Red Hat OpenShift baut dabei auf der Open-Source Software Kubernetes auf, erweitert es um eigene Features für einen vereinfachten DevOps-Betrieb (z.B. Registry per Imagestreams, Build-Jobs, integrierte Benutzeroberfläche und mehr) und bietet mit jedem Release zusätzlich Fixes für Defects, Sicherheits- und Performanceprobleme des Open-Source Kubernetes.
Lokales OpenShift
Für dieses „Getting started“ wird ein Minishift die Grundlage bilden. Dies ist eine schmalere Version von OpenShift. Es enthält ein OpenShift-Cluster mit nur einem Node und kann auf dem lokalen Rechner als virtuelle Maschine (VM) aufgesetzt werden. So eignet es sich gut für Übungen zum Kennenlernen von OpenShift oder lokales Development. Es ist sehr vielfältig einsetzbar und kann so auf den Betriebsystemen Windows, Linux und macOS verwendet werden. Es wird eine Virtualisierungssoftware für die Bereitstellung der VM auf dem lokalen Rechner benötigt. Auf allen Plattformen ist VirtualBox von Oracle nutzbar, ansonsten verwendet Windows Hyper-V, Linux kvm und macOS hyperkit.
Für die Bereitstellung der verschiedenen Virtualisierungsumgebungen gibt es unter folgendem Link (https://docs.okd.io/3.11/minishift/getting-started/setting-up-virtualization-environment.html) jeweils eine kurze Anleitung. Beispielhaft wird Minishift im Rahmen dieses Beitrags auf Windows verwendet. Die Virtualisierungsumgebung wurde gemäß der verlinkten Dokumentation unter Windows mithilfe von Hyper-V, einem Windows-Feature, vorbereitet.
Nachdem alle notwendigen Vorbereitungen (Aktivierung von Hyper-V-Feature, Berechtigungsanpassung und Erstellung eines virtuellen, externen Switches) getroffen wurden, kann Minishift in einer lokalen VM erstellt werden. Dazu werden die entsprechenden Dateien von https://github.com/minishift/minishift/releases heruntergeladen. Die enthaltene Binary-Datei minishift.exe muss im entsprechenden PATH-Pfad des Nutzers abgelegt werden. Dieser ist unter Windows normalerweise: %USERPROFILE%/AppData/Local/Microsoft/WindowsApps. Von nun an sollte der Befehl „minishift“ in der Commandozeile verfügbar sein. Dies kann mithilfe des folgenden Befehls überprüft werden:
minishift –help
Um die Erstellung der Minishift-VM zu vereinfachen, kann vor dieser noch der folgende Befehl ausgeführt werden:
minishift config set hyperv-virtual-switch “{switchName}”
Er setzt den entsprechenden Hyper-V Switch als Standardwert. Dazu wird der vorher vergebene Name des Switches benötigt. Ohne dieses Kommando muss beim Start von Minishift immer der entsprechende Switch als Parameter mitgegeben werden.
minishift start –hyperv-virtual-switch “{switchName}”
Das Kommando „minishift start“ sollte dabei am besten mit Administratorberechtigungen ausgeführt werden.
Nach der erfolgreichen Erstellung der VM kann mit dem OpenShift Cluster auf zwei Arten interagiert werden. Zum einen ist die Nutzung der GUI-Oberfläche im Browser möglich. Dazu muss nur die entsprechende IP aufgerufen werden. Diese wurde am Ende der Minishift-Erstellung zusammen mit Anmeldeinformationen angezeigt. Sollte die IP nicht mehr zur Hand sein, kann sie mit dem folgenden Befehl in der Kommandozeile angezeigt werden:
minishift ip
Die andere Möglichkeit besteht darin, OpenShift mithilfe der Commandline anzusprechen. Dazu wird allerdings noch das OpenShift eigene Kommandozeilen-Tool oc benötigt. Dieses kann nach der Bereitstellung von Minishift einfach mithilfe der folgenden Befehle eingebunden werden:
minishift oc-env
eval $(minishift oc-env)
Anschließend ist der Befehl oc in der Kommandozeile verfügbar. Dies lässt sich überprüfen, indem beim Aufruf des folgenden Befehls keine Fehlermeldung aufkommt:
oc –help
Grundlegender Cluster-Aufbau
Nun haben wir unser eigenes kleines OpenShift Cluster bereitgestellt. Aber wie ist solch ein Kubernetes/OpenShift-Cluster eigentlich grundlegend aufgebaut?
Ein Cluster besteht zuallererst aus den zwei Ressourcenbestandteilen Control Plane und Nodes. Im Cluster übernimmt die Control Plane die Managementaufgaben. So steuert sie alle Aktivitäten des Clusters, wie die Planung, Erhaltung und Aktualisierung der Applikationen. Des Weiteren werden die Apps entsprechend der Last durch die Control Plane skaliert. Bereitgestellt werden die Applikationen schlussendlich in den Nodes. Dies können VMs oder physische Maschinen sein, die vom Cluster als „worker machines“ genutzt werden. Innerhalb jedes Nodes gibt es einen Kubelet-Agenten, der für die Kommunikation mit der Control Plane zuständig ist, und ein Werkzeug für die Handhabung von Containern, z.B. Docker. Mit diesen grundlegenden Funktionen wird es der Control Plane erleichtert, die operativen Prozesse über die Nodes hinweg zu steuern.
Das Deployment auf den Nodes erfolgt über sogenannte Pods. In ihnen werden schlussendlich die Container und andere notwendige Ressourcen für den Betrieb der Anwendungen zur Verfügung gestellt und betrieben. Was genau ein Pod ist und welche Unterschiede es zwischen diesen und einfachen Docker-Containern gibt, wird in der nächsten Veröffentlichung unserer Reihe erläutert.
Da Kubernetes die Applikationen über die Pods flexibel verwaltet und skaliert, ist es notwendig, alle zusammengehörigen Pods genauso flexibel anzusprechen. Dazu nutzt Kubernetes Services. Diese legen die Erreichbarkeit zwischen den Ressourcen mittels Regeln fest. Genaueres dazu wird im Rahmen unseres Networking-Beitrags der Veröffentlichungsreihe dargelegt. Um von außerhalb von OpenShift auf die Pods zuzugreifen, ist meist noch eine sogenannte Route erforderlich. Diese fungiert prinzipiell wie ein Service, leitet aber die Anfragen von einer public URL zu einem definierten Port eines Service weiter, welcher dann die Verbindung zum Pod herstellt.
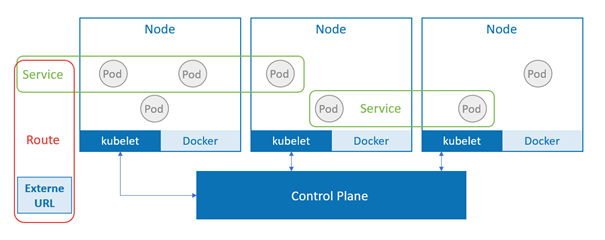
Abbildung 1: Schema des grundlegenden Cluster-Aufbaus
How to OpenShift mittels GUI
Um den Umgang mit Kubernetes am Beispiel von OpenShift zu zeigen, wird auch in diesem „Getting started“ ein httpd-Server bereitgestellt/eingerichtet. Die Arbeit mit OpenShift kann dabei über zwei Wege erfolgen. Es ist möglich, alle Aufgaben über die vorhandene GUI-Oberfläche von OpenShift durchzuführen. Dazu muss die am Ende der Minishift-Installation angezeigte IP-Adresse in einem Browser aufgerufen werden, um die Übersichtsseite (ggf. Anmeldung mithilfe der nach der Installation angezeigten Anmeldeinformationen) zu erreichen. Wer die Arbeit über die Commandozeile bevorzugt, kann mit OpenShift auch über die CLI “oc” kommunizieren und arbeiten. Dazu sind die bereits beschriebenen Schritte zum Einbinden von oc nach der Minishift-Installation durchzuführen.
Zur Erstellung eines neuen Deployments muss in der GUI sichergestellt werden, dass die Developer-Ansicht selektiert ist. Dazu den entsprechenden Bereich (</> Developer) oben in der Navigationsleiste auswählen.
Anschließend kann „+Add“ in der Leiste ausgewählt werden. OpenShift zeigt nun eine Menge verschiedener Möglichkeiten, wie ein Deployment erstellt werden kann.
Dazu zählen:
- Samples – Beispiel-Applikationen, die von Red Hat zur Verfügung gestellt werden
- From Git – Sogenannte S2i-(Source to image)-Verfahren
- Container Image – Erstellung erfolgt direkt aus einem bestehenden Container-Image
- From Dockerfile – Dockerfile wird genutzt, um ein Image zu generieren und dieses für das Deployment zu nutzen
- YAML – Resource entsprechend der YAML-Definition erstellen
- From Catalog – Nutze bereits hinterlegte Katalog-Applikationen
- Database – Katalog an unterstützten Datenbanken
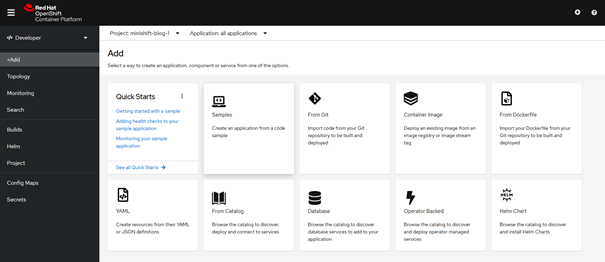
Abbildung 2: Die Developer-Ansicht in der GUI bietet verschiedene Optionen, ein Deployment zu konfigurieren
Um einen httpd-Server aufzusetzen, könnte so zum Beispiel das unter Samples bereitgestellte Httpd-Template genutzt werden. In dieser vorbereiteten Version wird schlussendlich ein Source-to-Image(S2I)-Verfahren genutzt, um den httpd-Server zu erstellen. In einem unserer späteren Blogbeiträge „Erstellung eines Image“ wird das Verfahren und dessen Ablauf erläutert. In der CLI könnte das Template über den folgenden Befehl gestartet werden:
oc new-app centos/httpd-24-centos7~https://github.com/sclorg/httpd-ex
Um das Vorgehen in unserem vorhergehenden Beitrag „Docker Getting Started“ nachzuempfinden, wollen wir unsere Applikation aber auch direkt aus einem Image erzeugen. Dazu kann in der GUI der Button „Container Image“ ausgewählt werden. In der Eingabemaske muss ganz oben das zu nutzende Image angegeben werden. Die Angabe httpd:{tag} würde hier bereits ausreichen, um das Docker-Image von Dockerhub beim Deployment zu beziehen. Da Container in OpenShift per Design mit beschränkten Rechten (rootless) ausgeführt werden, wird es beim Start der Anwendung zu einem Fehler kommen. Auf diesen Unterschied bezüglich der Container-Rechte in Docker und OpenShift wird in einem späteren Beitrag unserer Veröffentlichungsreihe (Rootfull vs. Rootless) noch genauer eingegangen.
Images von Dockerhub sind aus diesem Grund immer mit Vorsicht zu genießen, wenn sie in OpenShift genutzt werden sollen. Diese können, müssen aber nicht mit OpenShift funktionieren. Gegebenenfalls sind diese selbstständig anzupassen.
Red Hat stellt unter https://catalog.redhat.com/software/containers/search eine eigene Image-Übersicht zur Verfügung. Dort aufgelistete Images sind für die Nutzung mit OpenShift geprüft und freigegeben. Aus diesem Grund entscheiden wir uns bei der Erstellung des httpd-Servers in OpenShift für ein entsprechendes Image von Red Hat.
Im Feld „Image name from external registry“ geben wir deshalb „registry.redhat.io/rhel8/httpd-24“ an. Anschließend kann eine Abbildung (zum Beispiel das Apache Logo) für den Topologie-Plan ausgewählt werden. In diesem werden später sämtliche Pods des Projekts übersichtlich angezeigt. Unter General und Applikation kann dann der Name für unsere Applikation frei vergeben und ein Gruppenname angegeben werden, innerhalb dessen die Pods in der Übersicht später gegliedert werden. Für unseren einzelnen httpd-Server ist das allerdings nicht notwendig.
Schlussendlich kann noch gewählt werden, welche Ressource für das Deployment angelegt wird. Dabei besteht die Wahl zwischen einem Deployment, einer Ressource basierend auf dem zugrundeliegenden Kubernetes oder einer DeploymentConfig, der OpenShift-spezifischen Lösung.
Für unser Beispiel ist es dabei prinzipiell egal, welche Option ausgewählt wird. Es wird empfohlen, immer Deployments zu nutzen, solange keine spezifische Funktionalität der DeploymentConfigs benötigt wird.
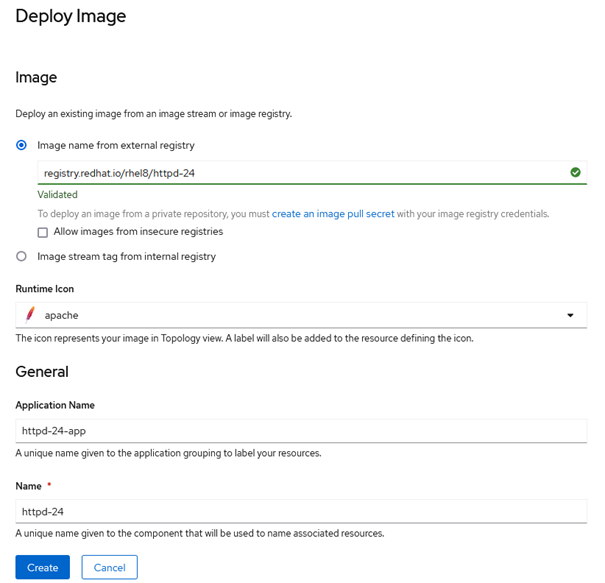
Abbildung 3: Erstellung eines httpd-Servers mit einem geprüften Image von Red Hat
Unter dem Abschnitt „Advanced Options“ gibt es noch die Möglichkeit, die Erzeugung einer Route an- beziehungsweise abzuwählen. Dabei wird entschieden, ob die zu erzeugende Applikation direkt mit einer URL freigegeben werden soll. Diese URL generiert OpenShift in diesem Fall automatisch. Um unseren httpd-Server anschließend aufrufen zu können, wählen wir diese Option. Durch Anklicken der weiteren, blau hervorgehobenen Links Routing, Health Checks, Deployment, Scaling, Resource Limits oder Labels können noch weitere Optionen für das Deployment ausgewählt werden. In unserem Fall sind diese aber erst einmal nicht wichtig. Mit „Create“ wird die Erstellung des httpd-Servers schlussendlich gestartet. In der Topologie-Überschicht wird das Deployment (D) nun als Kreis, mit der vorher ausgewählten Abbildung, dargestellt.
Der hellblaue Kreis, siehe Abbildung, zeigt, dass die Erstellung des Containers noch läuft, während ein dunkelblauer Kreis, angibt, dass das Deployment erfolgreich abgeschlossen ist. Rote und gelbe Umrandungen stehen für aufgetretene Fehler.
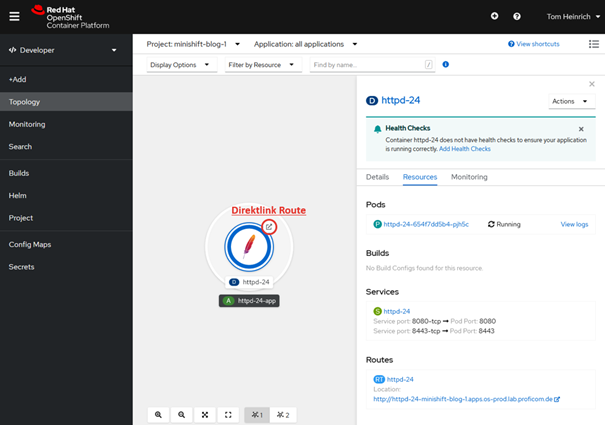
Abbildung 4: Übersicht der Standardinformationen des erzeugten Containers
Nach Auswahl des Containers, wird eine Übersicht auf der rechten Seite eingeblendet. Darin sind die zugehörigen Pods, Builds, Services und Routes aufgelistet. Die URL zu unserem Web-Server finden wir hier. Außerdem kann die Route, unter Nutzung des kleinen Symbols in der oberen rechten Ecke des Kreises, auch direkt geöffnet werden. So öffnet sich direkt ein neuer Tab. Es sollte die folgende Seite zu sehen sein. Der httpd-Server läuft.

Abbildung 5: Das Ergebnis ist ein funktionsfähiger httpd-Server
Um einen Überblick über alle bestehenden Elemente der verschiedenen Ressourcentypen zu bekommen, ist in der GUI ein Wechsel in die Administator-Ansicht notwendig. Dazu oben in der Navigationsleiste Administrator anstelle von Developer auswählen.
Die Navigationsleiste verändert sich nun und bietet eine Menge zusätzlicher Auswahlmöglichkeiten. Unter Home -> Projects kann ein Überblick über alle für den angemeldeten User freigegebenen Projekte erworben werden. Im Bereich Workloads können unter anderem alle Pods, Deployments und Deployment Configs angezeigt werden, während die bestehenden Services und Routen unter dem Punkt Networking zu finden sind. Mit allen Ressourcen kann anschließend über das Aktionsmenü (drei Punkte) am rechten Rand der Auflistungen direkt interagiert werden. So bietet sich an dieser Stelle z.B. die Möglichkeit, die jeweilige Ressource auch wieder zu löschen.

Abbildung 6: Die Administrator-Ansicht bietet zusätzliche Optionen zur Ressourcenverwaltung
How to OpenShift über CLI
Die bisher beschriebenen Schritte im OpenShift-Frontend lassen sich auch über die Commandozeile durchführen. Dazu muss zuerst eine Verbindung mit dem OpenShift Cluster hergestellt werden. Nach der Minishift-Installation ist bereits eine Verbindung mit oc am Cluster hergestellt und die CLI kann genutzt werden. Für eine erneute Anmeldung wird der folgende Befehl genutzt:
oc login
Ohne Angabe einer Serveradresse merkt sich oc die letzte Clusterverbindung und versucht sich automatisch wieder darauf zu verbinden. Um sich an einem anderen Cluster einzuloggen, muss die entsprechende Clusterschnittstelle an den obigen Befehl angefügt werden. Nach der Anmeldung werden die für den Nutzer zugänglichen Projekte angezeigt. Eine solche Übersicht zu den eigenen Projekten kann über den nachfolgenden Befehl angezeigt werden:
oc get projects
Zum Anlegen eines neuen Projekts wird das folgende Kommando genutzt. Die CLI wechselt anschließend automatisch in das neue Projekt:
oc new-project {project-name}
Durch die Verwendung des nächsten Kommandos kann außerdem das derzeit genutzte Projekt gewechselt werden:
oc project {project-name}
Im ausgewählten Projekt soll nun ein httpd-Server bereitgestellt werden. Dazu wird der folgende Befehl für die Erzeugung eines entsprechenden Pods mit dem Namen httpd-oc genutzt.
oc new-app –docker-image=registry.redhat.io/rhel8/httpd-24 –name httpd-oc
Der neu erzeugte Pod wird dann mithilfe des folgenden Befehls angezeigt:
oc get pods
Mit der Pod Erstellung wurde automatisch auch ein neuer Service generiert. Dieser kann über das folgende Kommando aufgelistet werden:
oc get services
Unser Webserver besitzt allerdings noch keine Route, weshalb es nicht möglich ist, über den Browser auf ihn zuzugreifen. Aus diesem Grund geben wir den zu unserem Pod gehörigen Service frei. Der Servicename ist über den vorherigen Befehl zu ermitteln:
oc expose service/httpd-oc
Nachdem dieser erfolgreich freigegeben wurde, können wir uns eine Übersicht der bestehenden Routen anzeigen lassen:
oc get routes
In der angezeigten Übersicht wird dann auch die Host-URL für den Webserver gezeigt. Über diese URL ist die oben bereits gezeigte Website des httpd-Servers erreichbar.
Falls Ressourcen nicht mehr benötigt werden, können diese entweder in der GUI über ihre entsprechende Aktionsleisten oder in der CLI über den Befehl „delete“ entfernt werden. Dabei muss immer der entsprechende Ressourcentyp und dann der Name der speziellen Ressource angegeben werden.
oc delete {type}/{name}
Das soll für diesen “Getting started“-Guide erst einmal reichen. Es wurde der grundlegende Aufbau von Clustern erläutert und neben dem Aufsetzen eines lokalen Minishifts in Windows auch die Bereitstellung eines httpd-Servers auf diesem dargelegt. Leider bietet dieser Beitrag nicht genügend Zeit, um auf alle Themen, die in ihm angeschnitten wurden, tiefgründig einzugehen. Freuen Sie sich aber darauf, dass diese und weitere Themen im Rahmen unserer Veröffentlichungsreihe „Docker vs. OpenShift“ zukünftig noch genauer beleuchtet und vorgestellt werden.

