
Die Reise des KI-Testens geht weiter. In diesem Kapitel werde ich mit den Qualitätsmerkmalen, die im vorherigen Kapitel ausführlich beleuchtet wurden, einen Schritt weiter gehen. Neben dem Entstehungsprozess konkreter Testfälle werde ich auch meine Erfahrungen teilen, wie ich diese in OpenText ALM Octane implementiert und ausgeführt habe. Die Resultate der Testausführungen lassen einen klaren Gewinner hervorgehen – also wer macht das Rennen? Der Übersetzer von Google, DeepL oder doch Libre Translate?
Schwerpunkte für das Testen: Testkriterien
Bevor es an die Realisierung von Testfällen geht, muss erst einmal feststehen, was denn eigentlich getestet werden soll. Denkt man an einen traditionellen Übersetzer wie dem Wörterbuch, soll die Übersetzung schlichtweg gut verständlich und präzise sein. Aber wenn ich mir jetzt vorstelle, dass ich eine E-Mail aus einer mir fremden Sprache ins Deutsche übersetzen soll, dann ist das schon eine große Herausforderung. Auch mit einem passenden Wörterbuch müsste ich Wort für Wort die richtige Übersetzung nachschlagen. Unterschiede in Grammatik und Satzbau zwischen den Sprachen sind dann noch mal eine andere Hausnummer.
Ein guter KI-Übersetzer sollte in der Lage sein, den Kontext eines Satzes zu verstehen und ihn entsprechend übersetzen. Die Genauigkeit und die Vollständigkeit der Übersetzung ist hierbei das A und O. Neben der Übersetzung von Fachtermini ist besonders wichtig, dass die Übersetzung in einen grammatikalisch sinnvollen und verständlichen Kontext eingebettet ist. Die ursprüngliche Bedeutung und Nuancen des Textes sollten möglichst beibehalten werden.
Auch die Vielfalt der Sprachen ist entscheidend. Jede der etwa 7000 unterschiedlichen Sprachen der Welt übersetzen zu können, ist selbst für ein maschinelles System eine große Herausforderung. Trotzdem sollten KI-Übersetzer im Stande sein, eine Vielzahl von Sprachen zu unterstützen sowie Sprachen automatisch zu erkennen, um Sprachbarrieren zu überwinden.
Neben der Erkennung von Sprachen sollten KI-Übersetzer auch Mehrdeutigkeiten erkennen und angemessen behandeln. „I just understand train station“ ist ein Paradebeispiel dafür, wenn man Sprichwörter Wort für Wort übersetzt.
Testfallerstellung und Risiken
Bei der Erstellung der Testfälle habe ich mich auf die Top 5 der meistgesprochenen Sprachen der Welt, sowie Deutsch, konzentriert. Der Grund für diese Auswahl ist die breite Abdeckung der weltweit gesprochenen Sprachen. Da ich selbst leider nur 3 der 6 Sprachen gewachsen bin – Deutsch, Englisch und Französisch – habe ich mir eine andere Herangehensweise überlegt, als schnell noch drei neue Sprachen zu lernen. Einen Übersetzer wie Google Translate zu nutzen, wäre sicher keine gute Idee, um damit Referenztexte für andere Systeme zu erstellen, vor allem nicht, wenn der Übersetzer letzten Endes selbst noch auf dem Prüfstand steht. Somit bin ich nach einigen Recherchen auf ein riesiges Testset von Microsoft gestoßen, das Ende November 2022 veröffentlicht wurde und Testdaten für 128 verschiedene Sprachen beinhaltet – darunter auch alle Sprachen, die ich betrachtet habe.
Auch wenn sich diese Testdaten als äußerst nützlich erwiesen haben, sollte man diese mit Vorsicht nutzen. Besonders bei Black-Box-Systemen wie DeepL ist nicht klar, welche Daten tatsächlich für das Training der KI genutzt wurden. Es besteht die Möglichkeit, dass genau diese öffentlich zugänglichen Informationen dafür verwendet wurden. In einer anschließenden Testdurchführung würde es dadurch zu Trugschlüssen über die tatsächliche Genauigkeit kommen. Die Systeme würden die Daten bereits kennen und man könnte keine Aussage darüber treffen, wie das System in neuen unbekannten Situationen abschneiden würde.
Wie schon im ersten Kapitel erwähnt, bieten sich ausreichend große Datenmengen durchaus an, maschinelle Metriken für die Auswertung zu nutzen. Zwei Wissenschaftler aus Jordanien haben genau das getan, indem sie unter anderem die Übersetzungen von Englisch in Arabisch aus Libre Translate mit anderen Tools verglichen haben. Aus dem Paper geht hervor, dass Libre Translate im direkten Vergleich mit den Übersetzungen anderer maschineller Übersetzer befriedigend abschneidet und mit Google Translate auf einem Level ist. Aber kann das sein, wenn doch meine ersten Eindrücke mit Libre Translate so enttäuschend waren?
Aus einer weiteren Studie ging hervor, dass journalistische Schreiben die größte Herausforderung für die KI-Übersetzer DeepL und Google Translate darstellten. Die Texte enthielten stilistische Mittel und andere Merkmale, die eine genaue und flüssige Übersetzung erschwerten. Aus diesem Grund und der zuvor beschriebenen Tatsache, dass die Daten von Microsoft öffentlich zugänglich sind, habe ich außerdem diverse Online-Zeitungsartikel aus der New York Times und anderen aktuellen Publikationen in die Testfälle eingebunden.
Die englischen Texte aus den Online-Zeitungen habe ich nach besten Gewissen selbst übersetzt und in meine Testfälle aufgenommen. Weitere Fälle wie die richtige Übersetzung von Fachbegriffen (zum Beispiel “Niereninsuffizienz” oder “Ösophagus”) oder auch die korrekte Verwendung von geschlechtsspezifischen Wörtern wie Berufsbezeichnungen sind auch Bestandteil meiner Tests. Wo KI-Übersetzer besonders gut punkten sollten, sind kontextabhängige Übersetzungen. Diese Eigenschaft habe ich anhand von deutschen Sprichwörtern und mehrdeutigen Begriffen genauer betrachtet. Hier sollten die KI-Systeme in der Lage sein, die Wörter nicht nur stumpf Wort für Wort zu übersetzen. Dennoch ist die Überprüfung der Systemausgabe nicht trivial. Ich muss vorher den Kontext analysieren und dann diesen in der Übersetzung wiedererkennen.
Realisierung der Testfälle in ALM Octane
ALM Octane von OpenText ist so etwas wie das Schweizer Taschenmesser für Qualitätssicherung in der Softwareentwicklung. Im Falle der KI-Übersetzer habe ich das Tool vor allem dafür genutzt, Testfälle und Testausführungen zu dokumentieren, um nicht den Überblick zu verlieren und sicherzustellen, dass alles reibungslos läuft. Auch die Darstellung der Testergebnisse konnte ich damit sehr einfach realisieren.
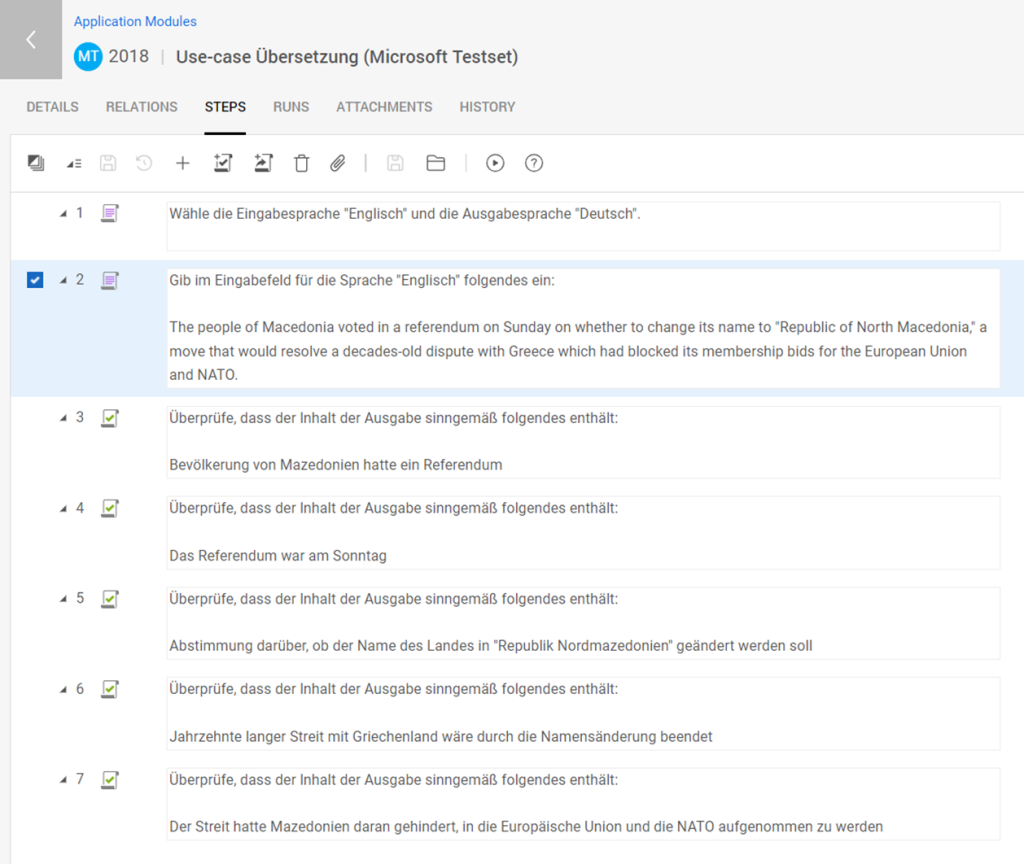
In dem obigen Beispiel habe ich einen Testfall erstellt, der die Übersetzung eines KI-Systems auf Vollständigkeit prüfen soll. Der Tester ruft dafür zunächst das zu testende System auf, wählt die Spracheinstellungen entsprechend der Vorgabe und kopiert den zu übersetzenden Text in die Eingabefelder des Systems. Anschließend prüft er schrittweise, ob die Übersetzung, die vom System zurückgegeben wurde, sinngemäß den tatsächlichen Inhalt wiedergeben. Ist das für jeden einzelnen Schritt der Fall, ist der Test bestanden, andernfalls wird er als „failed“ (engl. „fehlgeschlagen“) markiert. Für diesen Testfall muss beachtet werden, dass der Tester unbedingt eine Person sein muss, die der deutschen Sprache mächtig ist, da man hier dem Tester einen gewissen Interpretationsspielraum bei der Deutung der Übersetzung anvertraut.
Ausführung der Testfälle
Neben den bereits ausführlich vorgestellten Systemen Libre Translate und DeepL, wurden auch die Systeme Google Translate und Reverso genauer unter die Lupe genommen. Dabei war auch immer der Vergleich zu traditionellen Wörterbuchübersetzern wichtig, vertreten durch LEO Dict und dict.cc.

Im Software Testing sind die Begriffe „passed“ und „failed“ grundlegend, um die Qualität der getesteten Software zu verfolgen. Selbst wenn während der Ausführung der Tests nur ein einziger Schritt nicht zu dem Ergebnis führt, das erwartet wird, gilt der gesamte Test als fehlgeschlagen (engl. “failed”). Andernfalls wird der Test als bestanden markiert (engl. “passed”).
An dieser Stelle habe ich eine weitere Unterscheidung vorgenommen. Tests von Systemen, die KI-spezifische Features nicht unterstützen, wurden als „skipped“ markiert. Das trifft vor allem auf Testfälle zu, bei denen die Systeme kontextabhängige Übersetzungen liefern sollen. Somit kann in der Auswertung und Gegenüberstellung der Systeme in ALM Octane besser unterschieden werden, welche Systeme KI-spezifische funktionale Anforderungen erfüllen. Dazu zählt beispielsweise das Vorhandensein von Feedback-Loops (dt. “Feedback-Schleifen”) in der Form von Bewertungen der Übersetzungen, welche die Ausgabe eines KI-Systems und die entsprechenden Nutzeraktionen nutzen, um die Modelle im Laufe der Zeit neu zu trainieren und zu verbessern.
Auswertung der Ergebnisse
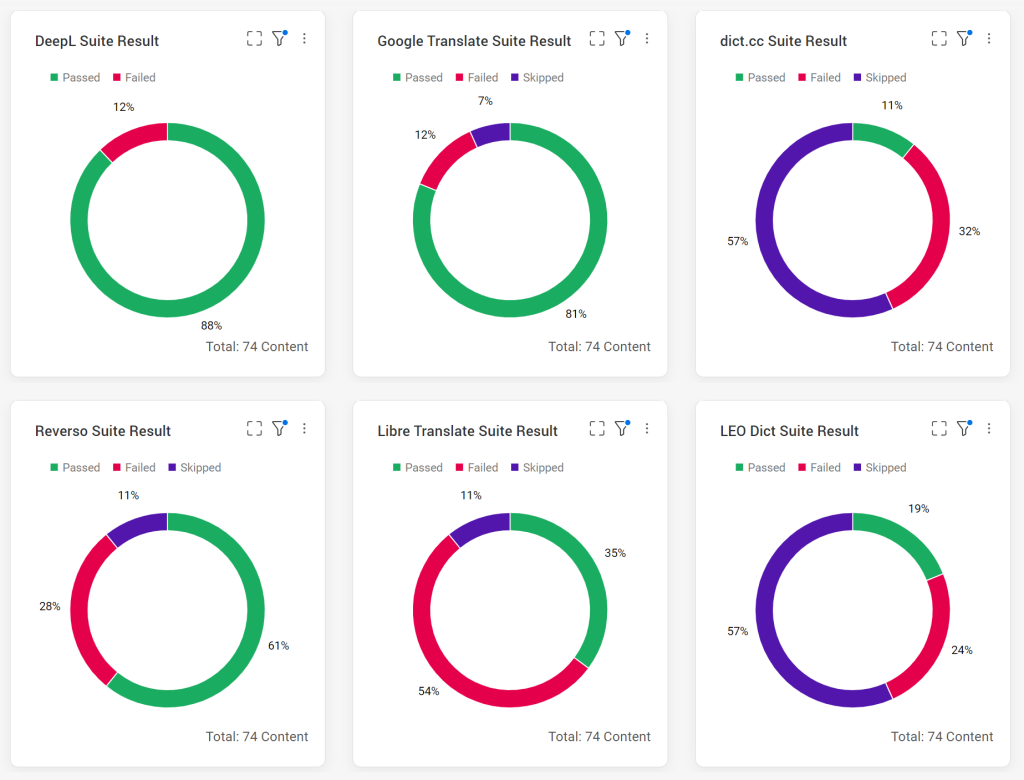
Betrachtet man die Zahlen des Dashboards, sticht DeepL klar hervor. Mein Anfangsverdacht, Libre Translate würde im Vergleich zu den anderen Systemen nicht so gut abschneiden, hat sich damit bestätigt – Libre Translate bildet das Schlusslicht. Dennoch muss beachtet werden, dass ich mich im Entwurf der Testfälle auf ein kleines Test-Set beschränkt habe – überwiegend waren es Übersetzungen von Deutsch nach Englisch und umgekehrt.
Für eine genauere Betrachtung der Übersetzungsqualität sollten maschinelle Metriken mit einem ausreichend großen Test-Set in Erwägung gezogen werden. Außerdem betrachten meine Tests vor allem funktionale Merkmale. Das Testen der nicht-funktionalen Merkmale sollte bei einer detaillierteren Auswertung zusätzlich in Betracht gezogen werden. Darunter zählen zum Beispiel die Benutzerfreundlichkeit oder Performanz der Systeme. Letztendlich hat in meiner Testumgebung keines der getesteten Systeme alle Tests bestanden.
Ein kurzer Ausblick
Im nächsten Kapitel widme ich mich einer Risikoanalyse in Bezug auf KI-Übersetzer. Dabei decke ich mögliche Risiken auf, die von KI-Übersetzern ausgehen und erkläre zudem welche Lösungen dafür eine Rolle spielen könnten.

